Explaining my research to a high school student


“If you can't explain it to a six year old, you don't understand it yourself.”
― Albert Einstein
In this post, I am going to take up a challenge. I don’t think I am at the level where I can explain my PhD research topic to a six year old. But I can try to explain it to a first year engineering undergraduate or a high school student as a starting point.
Let’s say you are in Hogwarts (who said research can’t be fun?). We have new students coming to Hogwarts, and we want to classify them into our houses: Gryffindor, Hufflepuff, Ravenclaw, and Slytherin. But unfortunately, our sorting hat has been stolen and Prof. Dumbledore has chosen one of his favorite student (you) to come up with a way to classify new students into houses. It is a hard task, but don’t worry, I am here to help you along with a few teachers from Hogwarts. Prof. McGonagall has taught you a magic spell, using which you can quickly find out a few characteristics of a student. For example, if the student is honest or not? Or if the student is loyal or not? And many other properties.
But that spell alone is not enough. You may know the characteristics of a student, but you also need to understand the characteristics of houses. You can use the already classified older students for understanding the house characteristics. On top of all that, you also have to make sure that your classification technique or algorithm is transparent and understandable by others. So, if a student is not happy with the house you assigned to them, you can always explain why you did so.
After studying a lot of mathematics, you decide to create a simple, easy to explain decision rule for each of the houses. One rule for Gryffindor, one for Hufflepuff, one for Ravenclaw and one for Slytherin. This rule will be based on the characteristics of a student. For example, the rule for Gryffindor could be: If a student is (brave AND emotional) OR (optimistic AND honest AND loyal) then the student deserves to be in Gryffindor. Similar for other houses. But how to create such rules?
That’s when you come to me. As a part of my research, I have studied a model developed by Sanjeeb Dash and others that can help with this task of creating rules. To use it, we need the data for our older students, who are already classified into different houses. Let’s pick Slytherin for example. We list the characteristics on the top and create a table with each row representing a student. Something like this.
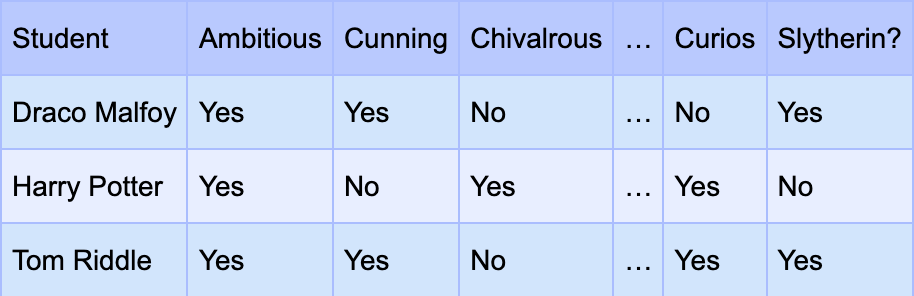
To make our lives easier, let’s label the characteristics as follows: Ambitious = x1, Cunning = x2, Chivalrous = x3 and so on. Let’s also replace the ‘Yes’ by 1 and ‘No’ by 0. The table will look something like this.
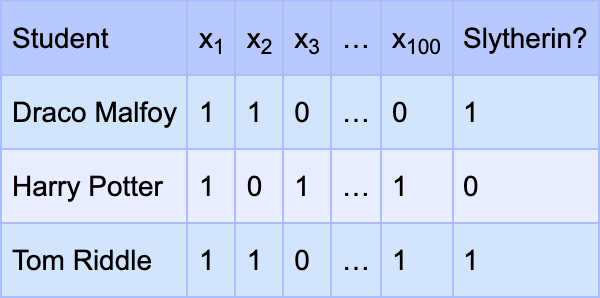
We want some of these characteristics to be part of our rule for Slytherin. We will design our rule in a particular format. It will be OR-of-ANDs. For example, (x1 AND x3) OR (x2 AND x4 and x7) OR (x13). This is also known as disjunctive normal form (DNF). Each AND term in the brackets like (x1 AND x3) is a clause. So, if a student has all the characteristics of any bracket, or in other words, satisfies at least one of the clauses in the rule, they pass our rule test. Our task is now to just select a few clauses for our rule, and we are done. Let’s represent those clauses by w variables as follows: use w1 for (x1 AND x2), w2 for (x1 AND x3), …, w150 for (x1 AND x4 AND x7 AND x11), and so on. If w1 = 1, we use the clause (x1 AND x2) in our rule and if w1 = 0, we don’t. Similar for the other clauses.
Those rules need to have a few properties. First of all, a rule has to be simple and understandable. So, the rule can’t be very long. In other words, it can’t contain too many clauses. At the same time, the clauses should be small. We don’t like long clauses for, e.g., w150 (x1 AND x4 AND x7 AND x11). So let’s assign some complexity ck for each clause wk. The complexity is simply the number of characteristics it contains. But at the same time, we want to have fewer clauses, so let’s add 1 to the complexity for each new clause. The complexity is then ck = 1 + number of characteristics it contains. Let’s pick a good number for our maximum complexity for the rule. Say 10. So, we want,
\[\sum_k c_k w_k \leq 10 \]
The data we have for older students, should follow those rules. In other words, let’s say we have selected 3 clauses for our rule for Slytherin, then Malfoy and Riddle should satisfy at least one of those 3 clauses. This is hard to encode in a mathematical equation. Let’s go the other way around. We know what clauses Malfoy satisfies. So, we want to make sure that we select at least one of those clauses in our final rule for Slytherin.
For each Slytherin student, this can be written as a mathematical constraint, as follows. Let Ki be the set of clauses satisfied by the student i in Slytherin, then we want,
\[\sum_{k \in K_i} w_k \geq 1, for\, all\, i \in Slytherin\]
But there is a problem. It turns out that the students in Slytherin are quite diverse. There is no simple rule within our desired complexity that can classify each Slytherin student correctly. So, what to do? Let’s relax our last equation a little. We will design a rule, that correctly classifies ‘most’ students instead of ‘all’ students. So, that means, we will make some wrong classifications, but we will make sure that such wrong classifications are as few as possible. Let’s introduce a penalty variable Pi for each student i. We allow some Slytherin students to not satisfy our rule, and in that case, we want the penalty variable Pi to take value 1. So, we update our last equation for each Slytherin student i,
\[P_i + \sum_{k \in K_i} w_k \geq 1, for\, all\, i \in Slytherin\]
Finally, we also want to make sure that no student from some other house satisfy any of the clauses in our rule. Otherwise, we will wrongly put them in Slytherin. To achieve that, we compute the penalty for a non-Slytherin student like Ron, as the number of selected clauses they satisfy. If Ron satisfies three selected clauses, then we add 3 to the penalty. For a given non-Slytherin student, our penalty is,
\[N_i = \sum_{k \in K_i} w_k , for\, all\, i \in Other\, Houses \]
Our final objective is to minimize the total penalty, that is,
\[\sum_{i \in Slytherin} P_i + \sum_{i \in Other\, Houses} N_i\]
The complete problem looks like this,
\begin{align*} Minimize \quad & \sum_{i \in Slytherin} P_i + \sum_{i \in Other\, Houses} N_i \\ & \\ Subject\, to \quad & \sum_k c_k w_k \leq 10 \\ & P_i + \sum_{k \in K_i} w_k \geq 1, for\, all\, i \in Slytherin \\ & N_i = \sum_{k \in K_i} w_k , for\, all\, i \in Other\, Houses \end{align*}
How do we solve this? Fortunately, this happens to be an integer linear program. There are numerous solvers available that can solve this problem in this format. But there is one more issue. How many w variables do we have? One for each clause. How many clauses do we have? That’s hard to count. Each clause is made from characteristics. So for each characteristic, a clause has two choices, whether to contain it or not. Two choices for x1, Two for x2, and so on. In total, let’s say if we have 100 characteristics, the total number of clauses would be 2100. That’s too large. Our computers can’t even store that many variables, let alone solve a bunch of equations containing them.
Here we use an astonishing technique in optimization called ‘Column Generation’. This magical technique allows us to start solving the problem with a few w variables, say 5 or 10, and then add them to the problem as needed to get to the optimal answer. Hopefully, we will be able to solve the problem (find a solution with the smallest penalty possible) without having to use all the w variables.
Finally, using column generation, we solve the problem in a few minutes and come up with the following rules:
1) Slytherin: (Ambitious AND Leader AND Cunning) OR (Resourceful AND Self-preservative AND Cunning)
2) Ravenclaw: (Intelligent AND knowledgeable AND curios) OR (knowledgeable AND creative AND witty)
3) Hufflepuff: (Hard-working AND Dedicated) OR (Patient AND loyal AND Ethical)
4) Gryffindor: (Brave AND Confident) OR (Daring AND chivalrous).
You show these rules to Dumbledore. He is very pleased and granted your house 50 points for such outstanding work. The rules were successfully used to classify new students with a very high satisfaction rate. However, the hat is still missing. We must find the thieves and punish them. But we will do that some other day.
This house classification is an example of a usual classification task in a field called ‘Machine learning’. Overall, this is an example of how ‘Column Generation’ can be used in the big field of Machine learning. My research is about exploring, analyzing and creating algorithms in which column generation is applied in machine learning. The column generation is used in some other machine learning algorithms as well, for example, decision tree, SVM, Boosting, etc. I will try to explain how column generation works in some other post in the future.
Hope you liked this. Check out my other posts below and don't forget to subscribe.
References:
Harry Potter and the Philosopher's Stone, Chapter 7 (The Sorting Hat)
Sanjeeb Dash, Oktay Gunluk, and Dennis Wei. Boolean decision rules via column generation. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018.
Murat Firat, Guillaume Crognier, Adriana F. Gabor, C.A.J. Hurkens, and Yingqian Zhang. Column generation based heuristic for learning classification trees. Computers and Operations Research, 116, apr 2020.
Antoine Dedieu, Rahul Mazumder, and HaoyueWang. Solving l1-regularized svms and related linear programs: Revisiting the effectiveness of column and constraint generation, 2019.
Ayhan Demiriz, Kristin P. Bennett, and John Shawe-Taylor. Linear Programming Boosting via Column Generation. Machine Learning, 46(1):225–254, January 2002.